Monte Carlo Poker Simulation in C
Summary
Have you ever seen a poker game on TV and noticed the real-time odds of each hand winning in the corner of the screen? How does one compute these odds? This project is all about creating software that gives poker hand probabilities to arbitrary precision in C.
Goal
Create a Monte Carlo poker simulation entirely in C to estimate odds of winning for a given hand for Texas hold ‘em, five-card stud, and other poker variations.
Approach
Given a couple of poker hands and a single unknown (i.e., yet to be drawn) card, it would be possible (albeit a bit painful) to compute probabilities of a given hand winning by considering all possible outcomes using the remaining cards in the deck; with multiple unknown cards, however, this approach quickly becomes intractable. This is the reasoning for approaching this problem using a computer and a Monte Carlo simulation.
Even without the development of a fancy graphical user interface, this project is surprisingly complicated and extensive, requiring practically all of the basic elements of the C programming language: structs, arrays, dynamic memory allocation, layers of pointers, file I/O, and more. This was a project that put all of my knowledge of C to the test and really sharpened my C programming skills.
The first design choice is to select a data type for representing cards and decks in software, with structs being the obvious choice in C.
The program is designed to read a text file containing sets of hands for evaluation. Cards are identified with pairs of characters that indicate the value and suit, e.g., Kh for king of hearts, or 7s for seven of spades. Cards that are not yet known (and thus require a probabilistic evaluation by drawing from the remaining cards in the deck) are indicated with a question mark and a numerical identifier, e.g., ?3.
Consequently, card structs contain fields for value and suit. Some basic functions have to be written to print out cards, read in cards based on character pairs, rank cards by value, map unique cards to the range of integers [0, 52), and assert valid values of cards.
Decks are simply arrays of card pointers. The struct that defines a deck has a field for the array and a field for the number of cards stored in the array. More basic functions have to be written to print the cards in a deck, add and remove cards from a deck, shuffle a deck, determine if a deck contains particular cards, add and remove unknown cards from a deck, make decks with excluded cards, determine the number of matching values shared between two decks, and assert the validity of the cards contained in a deck.
The reason that decks contain arrays of pointers to cards instead of just an array of cards is that this architecture makes card replacement (an essential process when dealing with unknown cards) much easier. For example, consider a set of cards (a deck) containing (pointers to) an ace of hearts, a king of spades, a queen of clubs, and an unknown card that will later be replaced:
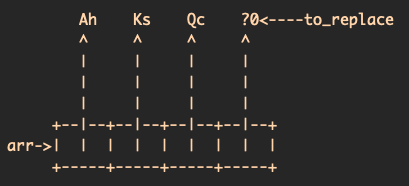
Then, you shuffle the deck such that the order now reads Ks, ?0, Ah, Qc:
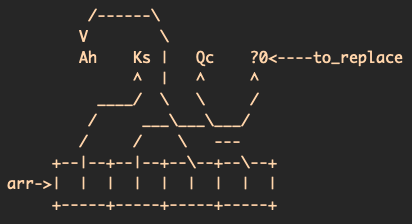
Because pointers to cards were used, when you later draw a card from the deck to replace the unknown card, the pointer still points to the memory location that requires replacement; this architecture makes replacement much easier later.
Since decks are really just an abstraction used to represent any collection of cards, they are also useful for representing the poker hands to be evaluated. The process of evaluating the hands using the rules of poker to determine a winner represents the most complicated part of the project. I suppose there isn’t much detail worth mentioning on this topic except that there are a surprising number of edge cases to consider when evaluating poker hands, with lots of pitfalls to be found when evaluating ace-high and ace-low straights, determining pairs vs three of a kind vs four of a kind, detecting straight flushes (a straight plus a flush does not make a straight flush, in general!), or implementing tiebreakers.
To test hand evaluation, a database consisting of hundreds of sets of hands (selected to provide good code coverage) were given to the software for evaluation, and the output checked against known outcomes also given in the database. To test the probability calculations, several sets of hands with incomplete information and known probabilities were given to the finished program. The Monte Carlo simulation is carried out by running trials, each time shuffling the deck and determining a winner. When enough trials are run, the probability of a hand winning is estimated using the ratio of wins for that particular hand to the number of trials. Probabilities can be estimated to arbitrary precision by increasing the number of trials. Even without code refactoring or compiling with optimization, the program can run hundreds of thousands of trials in a fraction of a second; this is easily enough for probability estimates to within 1% of ground truth.
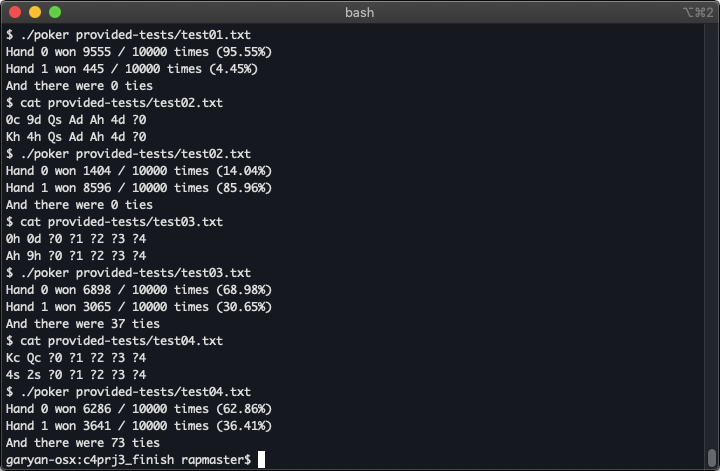
The final program is robust to errors and abnormalities in both the input files and command line arguments; has been thoroughly debugged using extensive white- and black-box testing; and Valgrind reports no memory leaks in any of the software components.